LLMDA Method
LLMDA Method
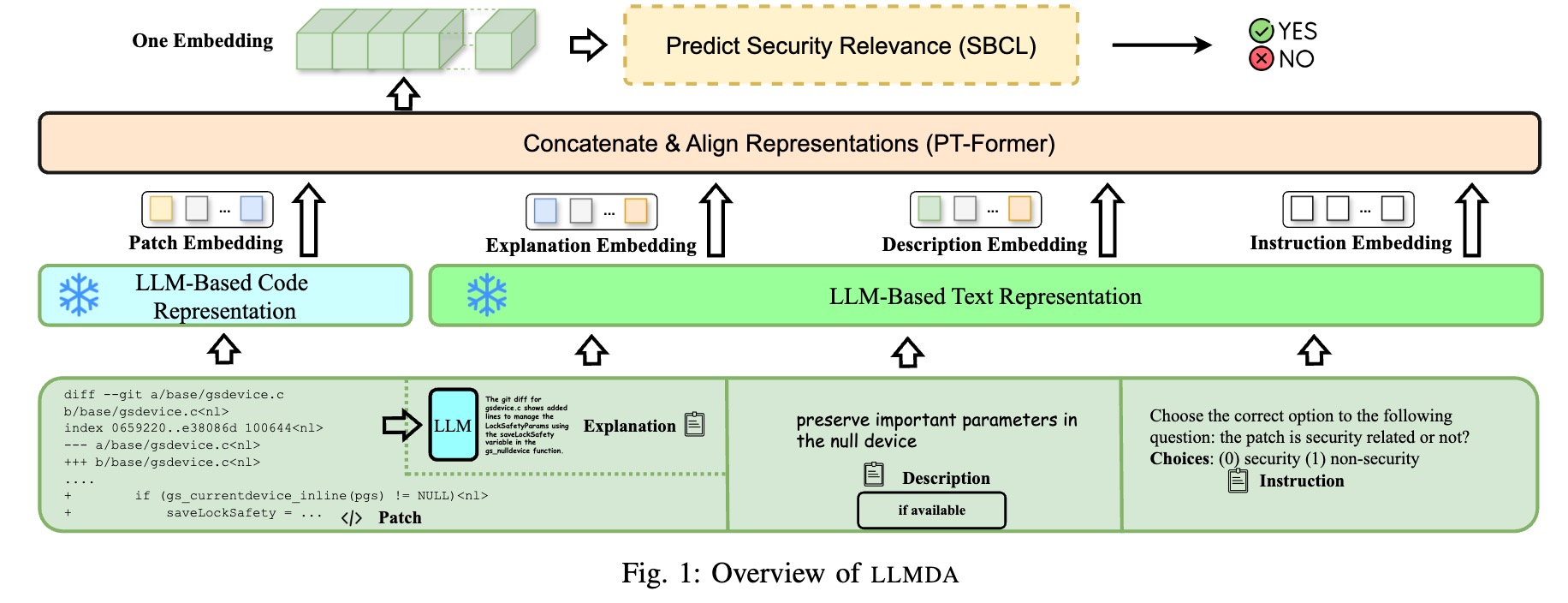
Figure 1 depicts the overview of the different steps of LLMDA. First, representations of multi-modal inputs (code and texts) are obtained using LLMs. Then, the obtained representations are aligned within a unique embedding space and fused into a single comprehensive representation by the PT-Former module. Finally, a stochastic batch contrastive learning (SBCL) mechanism is deployed to make the predictions of whether a given patch is a security patch or not.
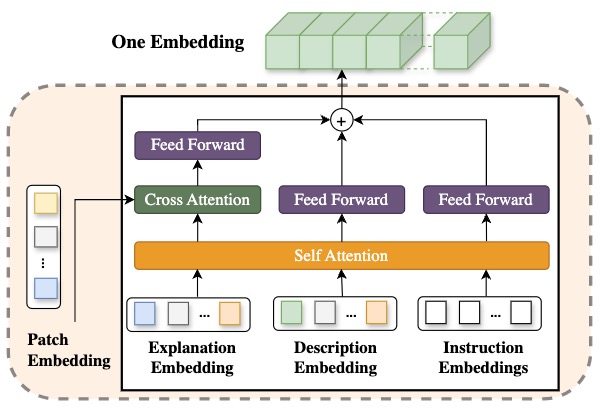
PT-Former innovatively addresses the challenge of fusing embeddings from different modalities—specifically, patches and texts—by introducing an architecture that aligns and concatenates embedding spaces to enhance the interpretability and effectiveness of classification models. Leveraging self-attention mechanisms, PT-Former updates individual embeddings, ensuring that the information carried by each is rich and contextually relevant. The cross-attention module further aligns the embeddings of code changes with their textual explanations, creating a nuanced understanding of the interaction between these two modalities. Finally, by employing feed-forward layers for non-linear transformation and concatenating the aligned embeddings, PT-Former achieves a comprehensive representation of the input data. This methodical approach not only bridges the gap between distinct feature spaces but also optimizes the process of embedding fusion, thereby enabling more accurate and insightful classification outcomes.
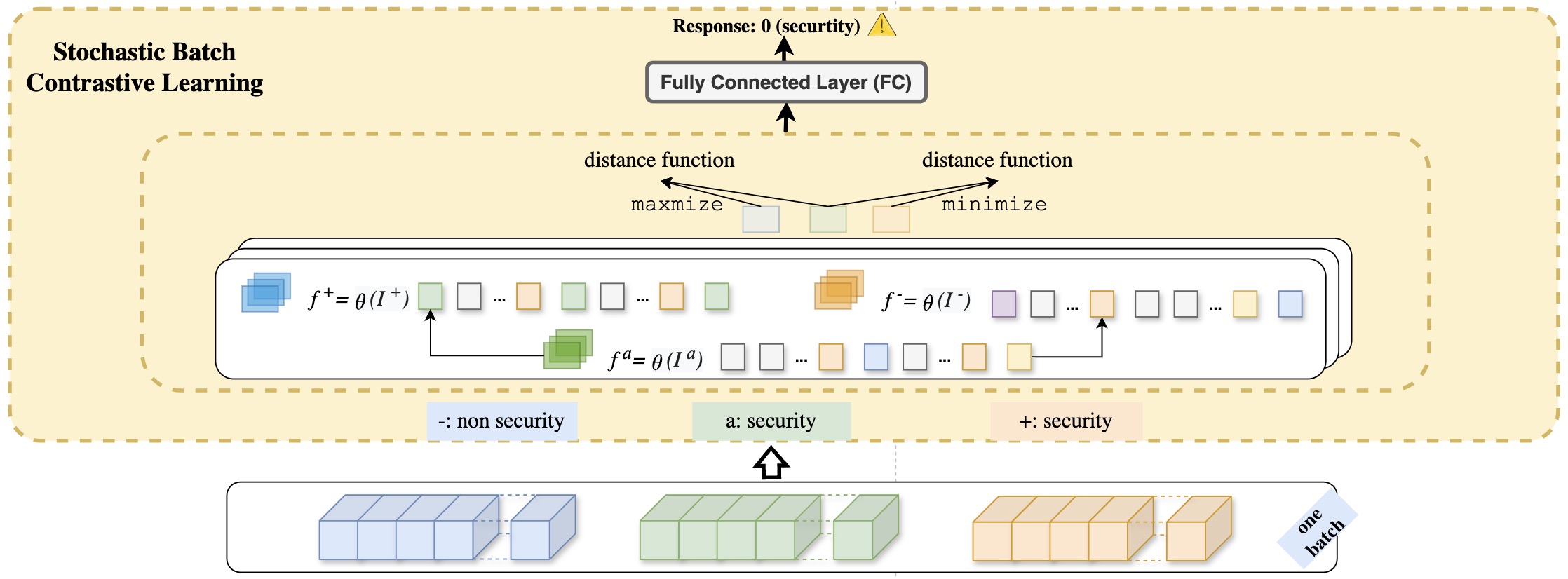
SBCL, standing for Stochastic Batch Contrastive Learning, serves as a sophisticated mechanism for refining the classification capabilities of a binary classifier tasked with distinguishing security patches from non-security patches. This mechanism operates on the premise of enhancing the classifier's ability to discern intrinsic patterns within a dataset, relying on embeddings output by PT-Former that encapsulate security patch characteristics along with their LLM-generated explanations, developer descriptions, and labelled instructions. SBCL innovatively utilizes batch sampling and triplet formation techniques to emphasize learning from both closely related security examples (positive pairs) and distinguishably different non-security examples (negative pairs), thereby optimizing the model's embedding space for precise security relevance prediction. Through the application of a stochastic batch contrastive loss, SBCL meticulously adjusts the embedding distances within each batch to ensure a clear demarcation between security-related and non-security-related examples. This strategic approach significantly bolsters the model's performance by fostering an embedding space that is both robust and discriminative, thereby setting a new standard for the identification of security patches.
Research Questions
Dataset

In this example, the model generates a comprehensive plan for the task, including subsequent actions on the following pages that are not currently visible.
A. Overall Performance
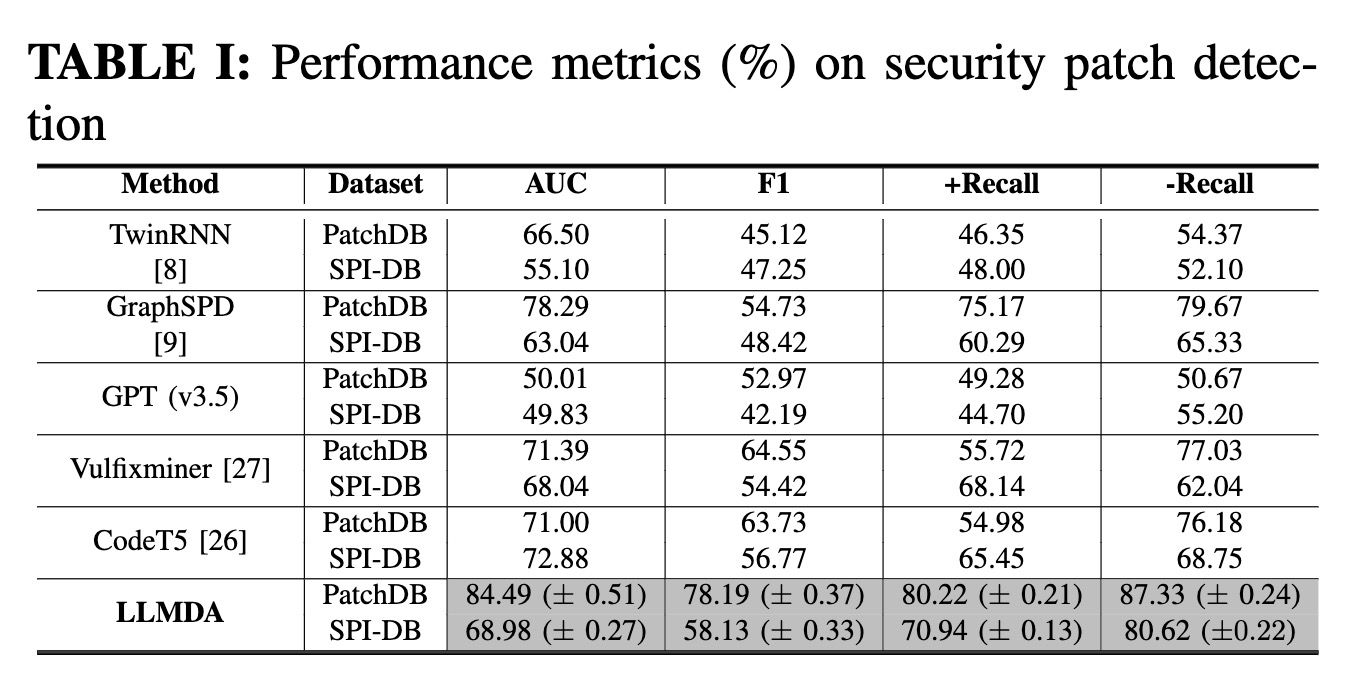
LLMDA is effective in detecting security patches.With an F1 score at 78.19%, LLMDA demonstrates a well-balanced performance: our model can concurrently attain high precision and high recall. Specifically, we achieved a new state-of-the-art performance in identifying both security patches (+Recall) and recognizing non-security patches (-Recall). Comparison experiments further confirm that LLMDA is superior to the baselines and is consistently high-performing across the datasets and across the metrics.
B. Ablation Study
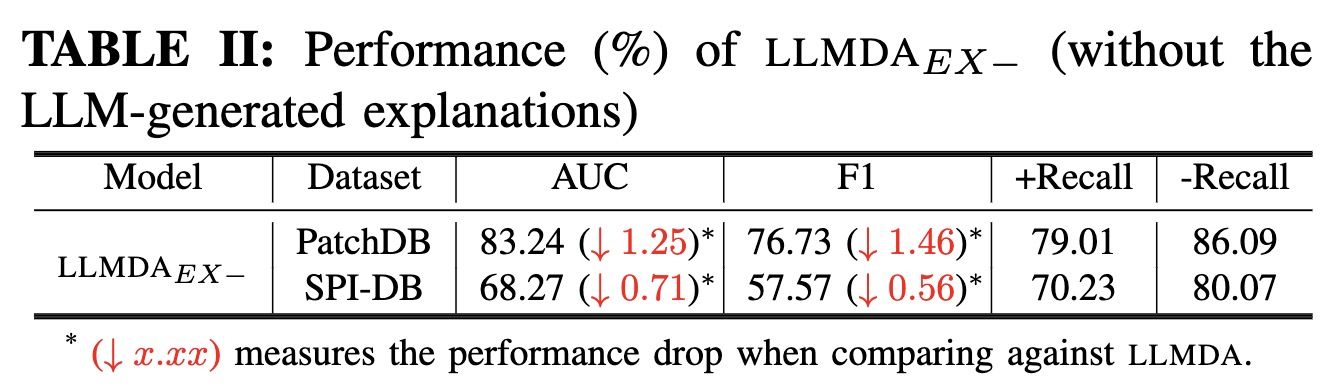
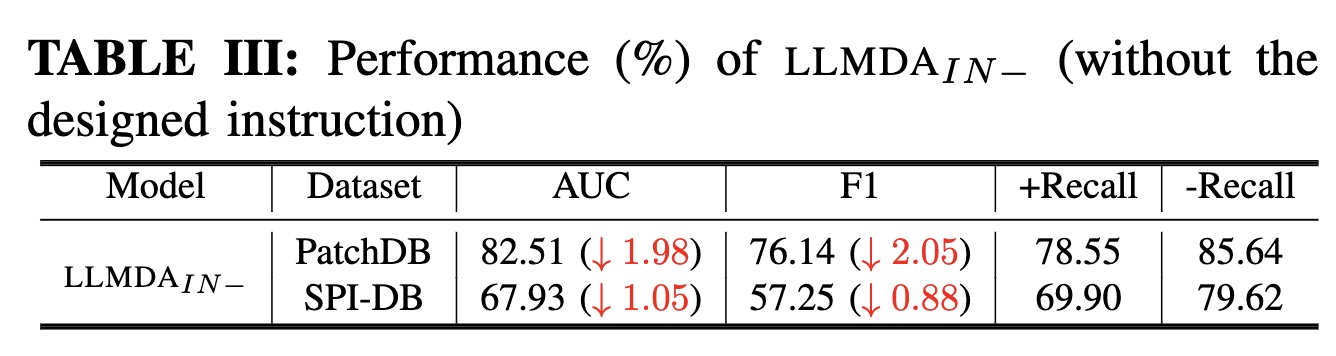
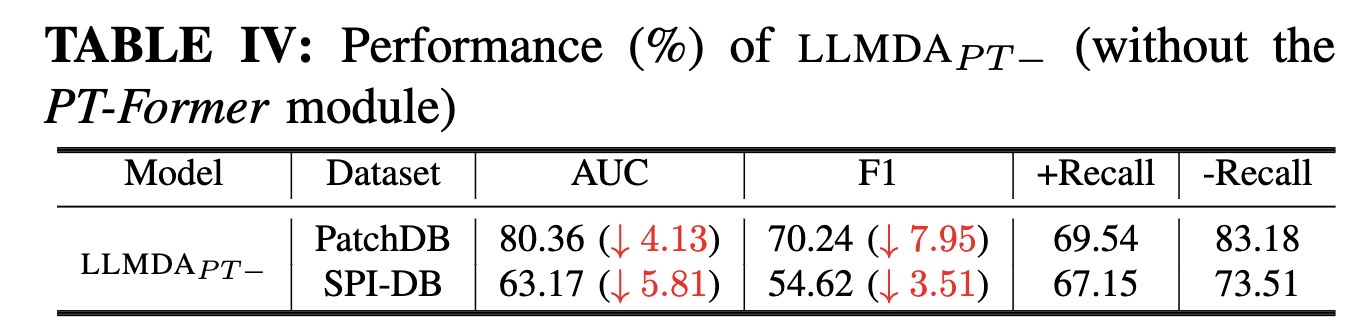
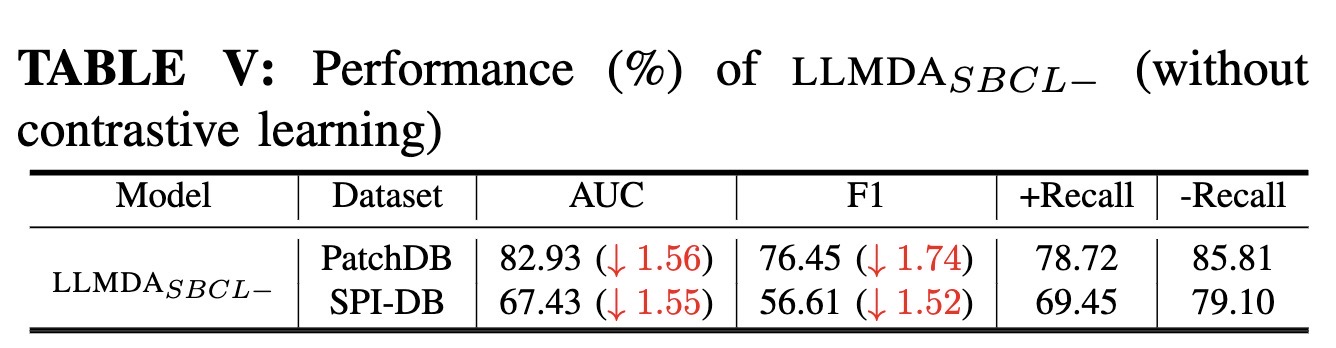
The ablation study results reveal that each of the key design decisions contributes noticeably to the performance of LLMDA. In particular, without the PT-Former module LLMDA would lose about 8 percentage points in F1
C. Visualizations
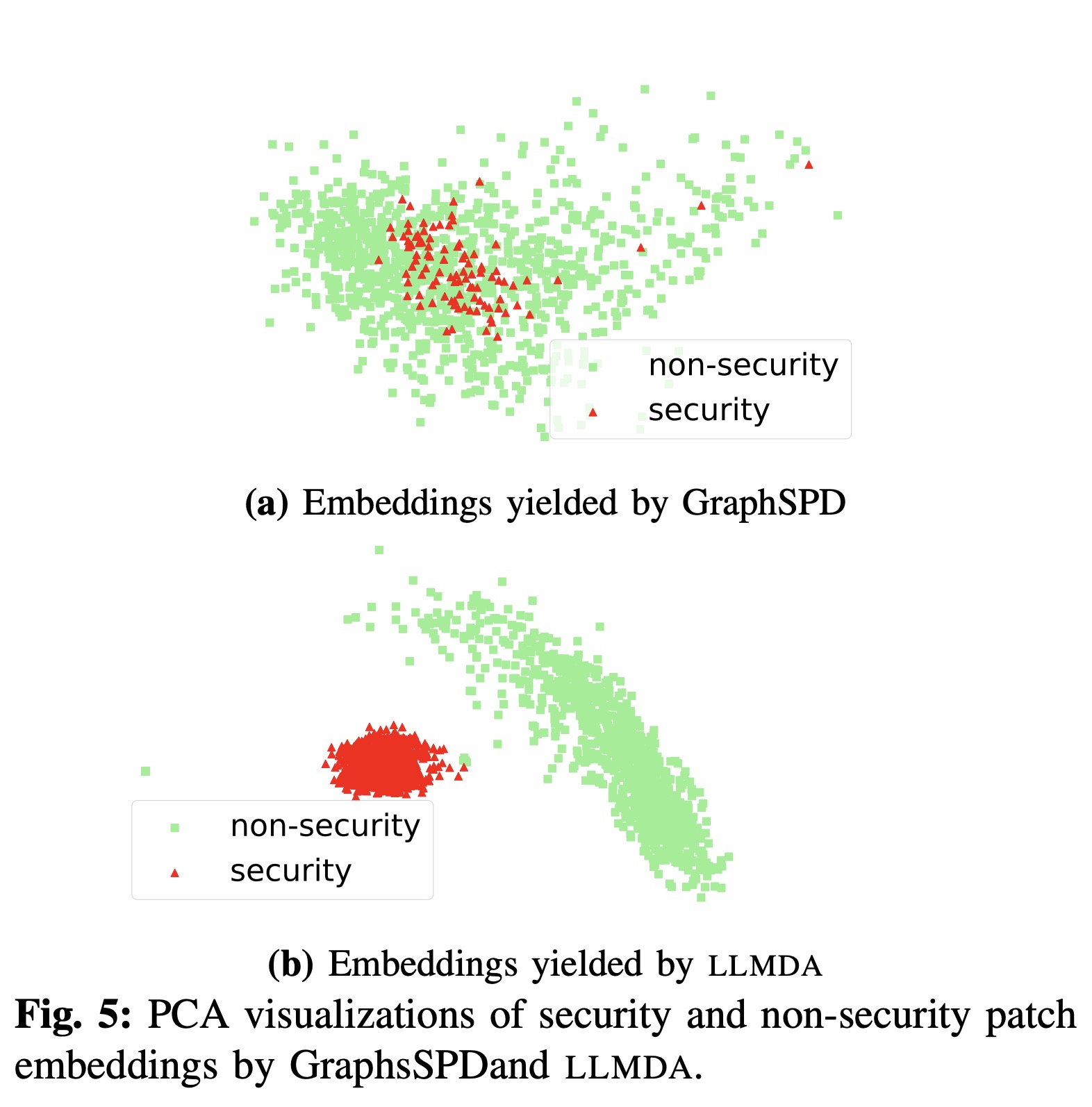
We consider 1 000 random patches from our PatchDB dataset. We then collect their associated embeddings from LLMDA and GraphSPD and apply principal component analysis (PCA) [30]. Given the imbalance of the dataset, the drawn samples are largely non- security patches, while security patches are fewer. Figure 5 presents the PCA visualizations of the representations. We observe from the distribution of data points that LLMDA can effectively separate the two categories (i.e., security and non-security patches), in contrast to the incumbent state-of- the-art, GraphSPD. This finding suggests that the representa- tions of LLMDA are highly relevant for the task of security patch detection.
D. Case Study

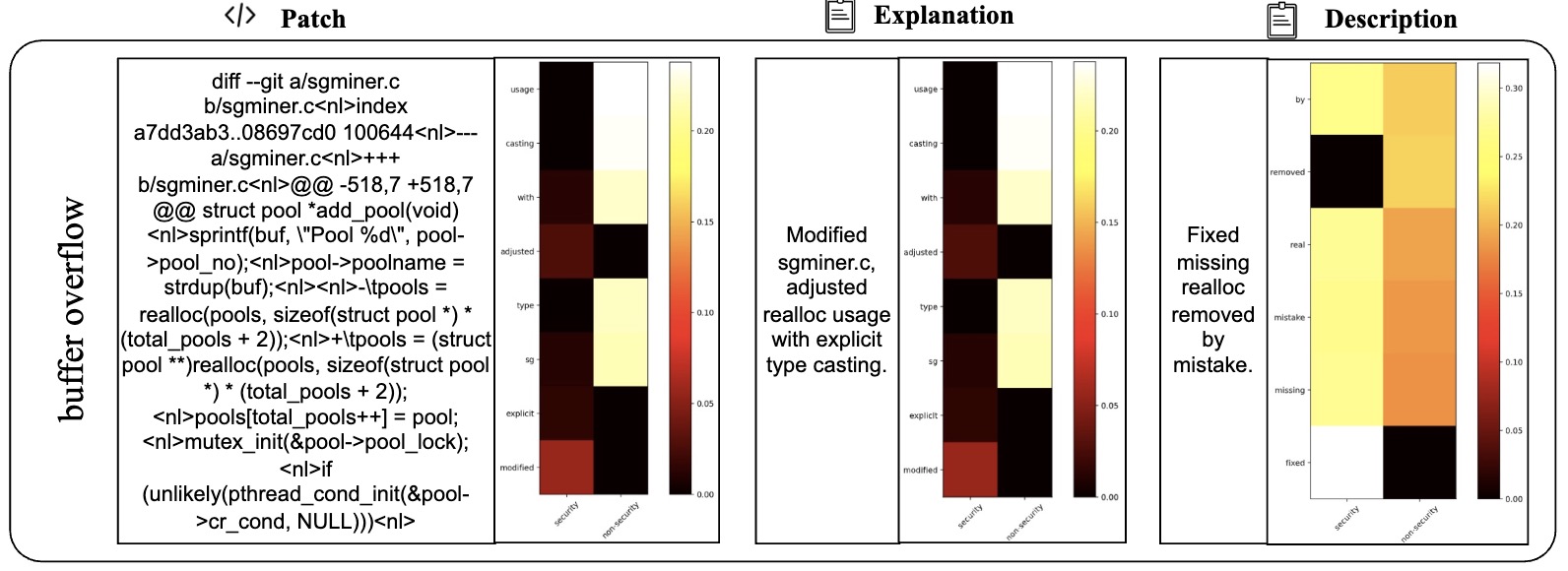
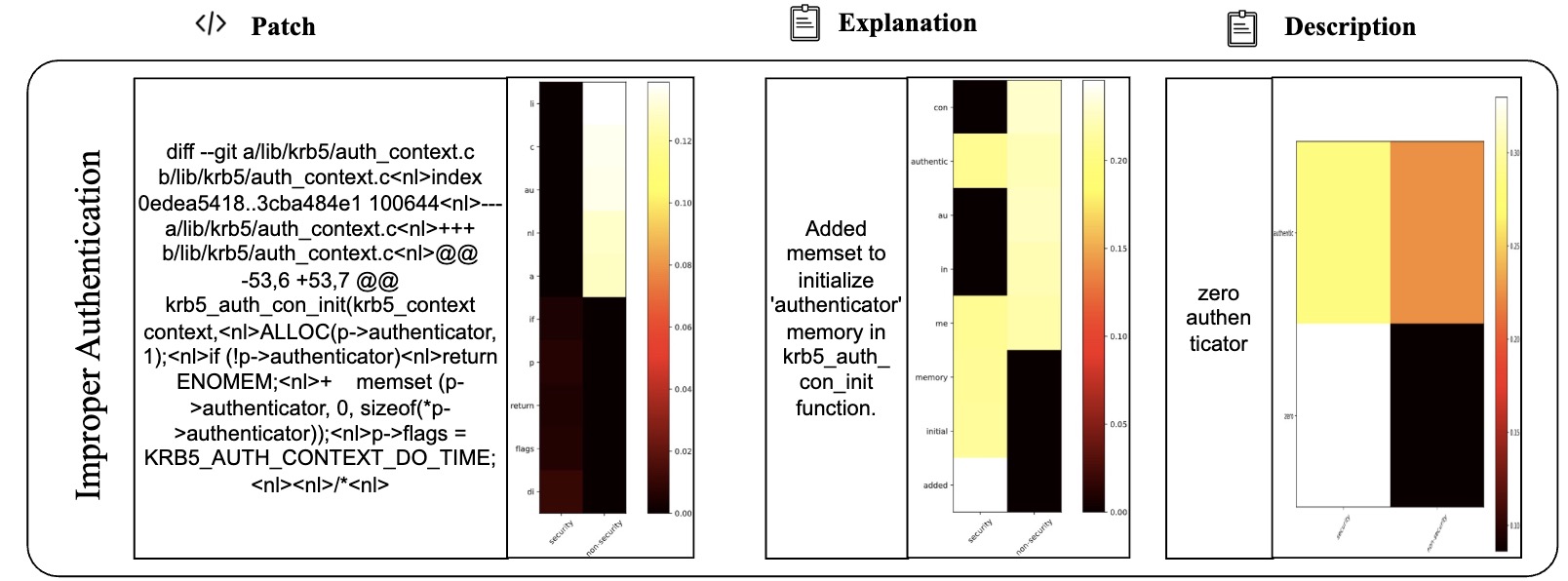
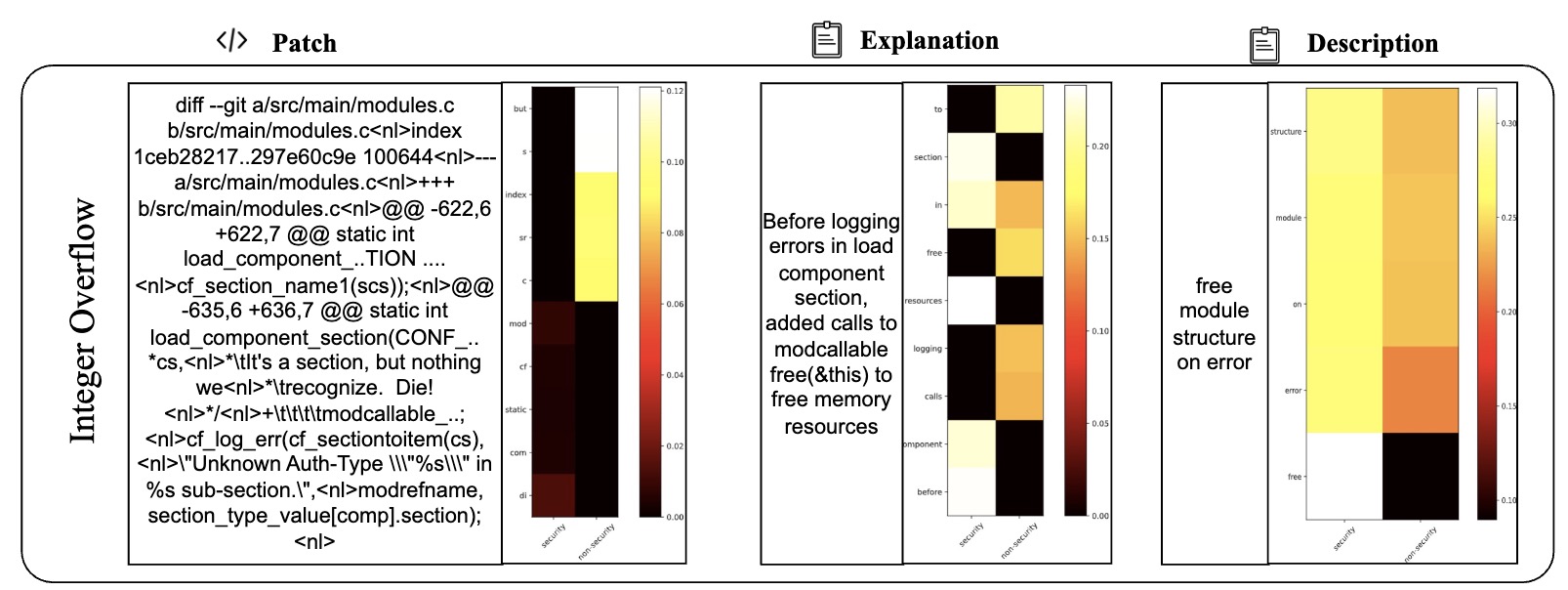
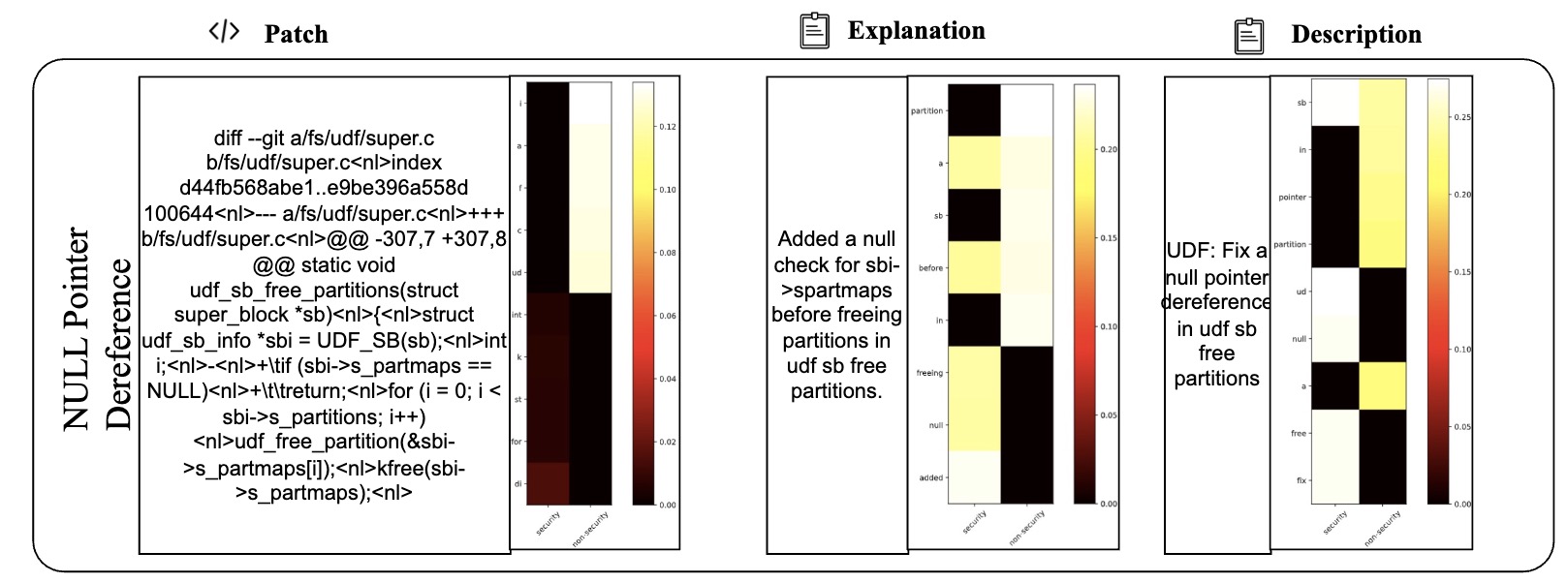
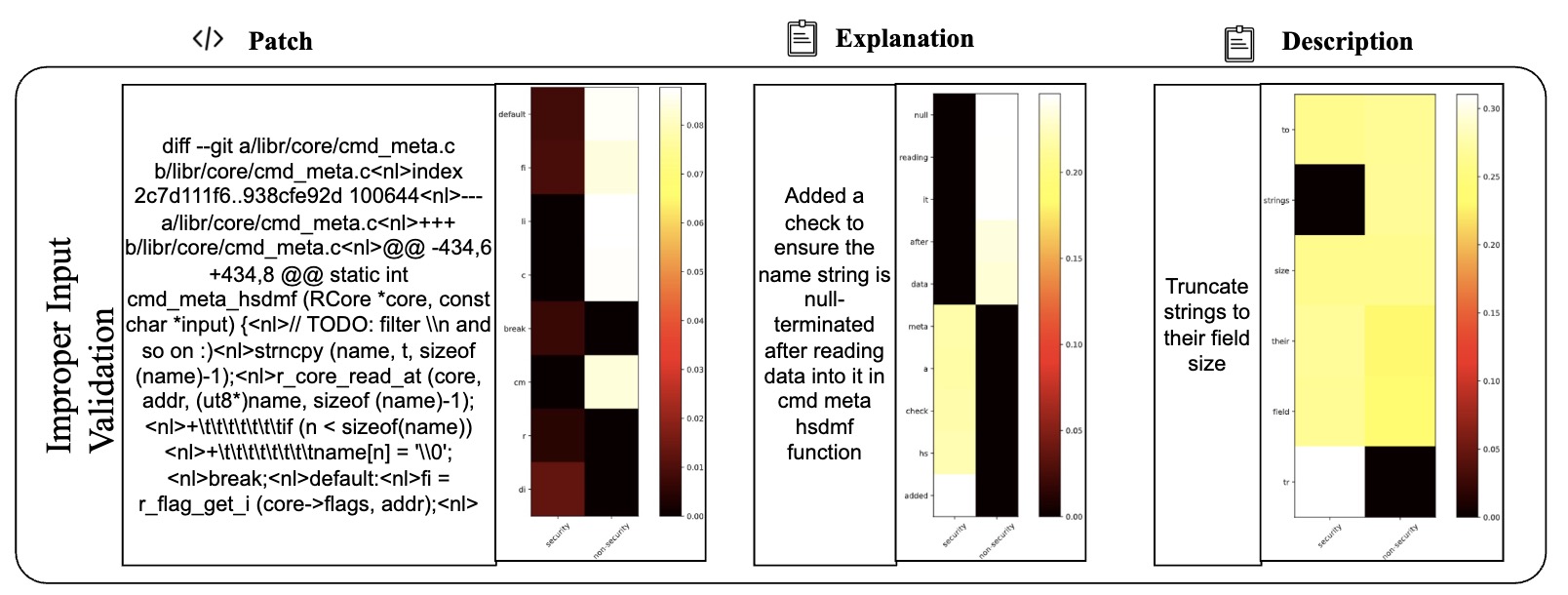
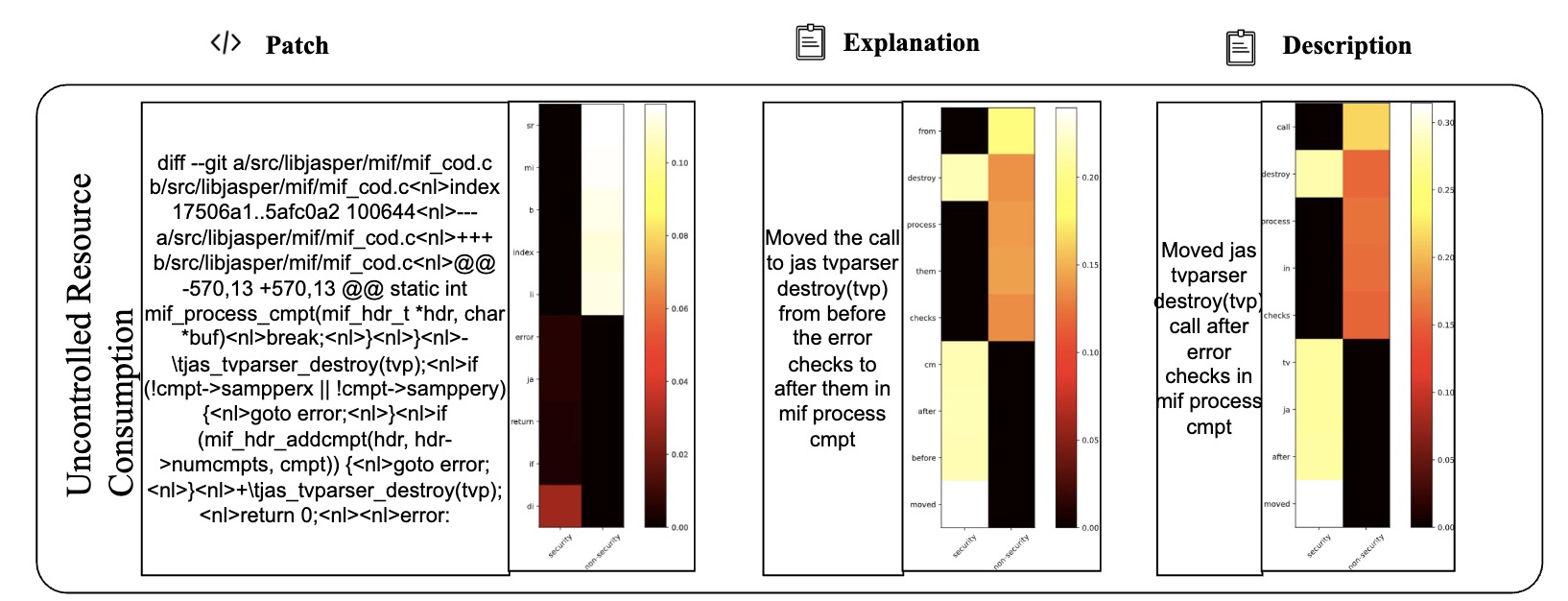
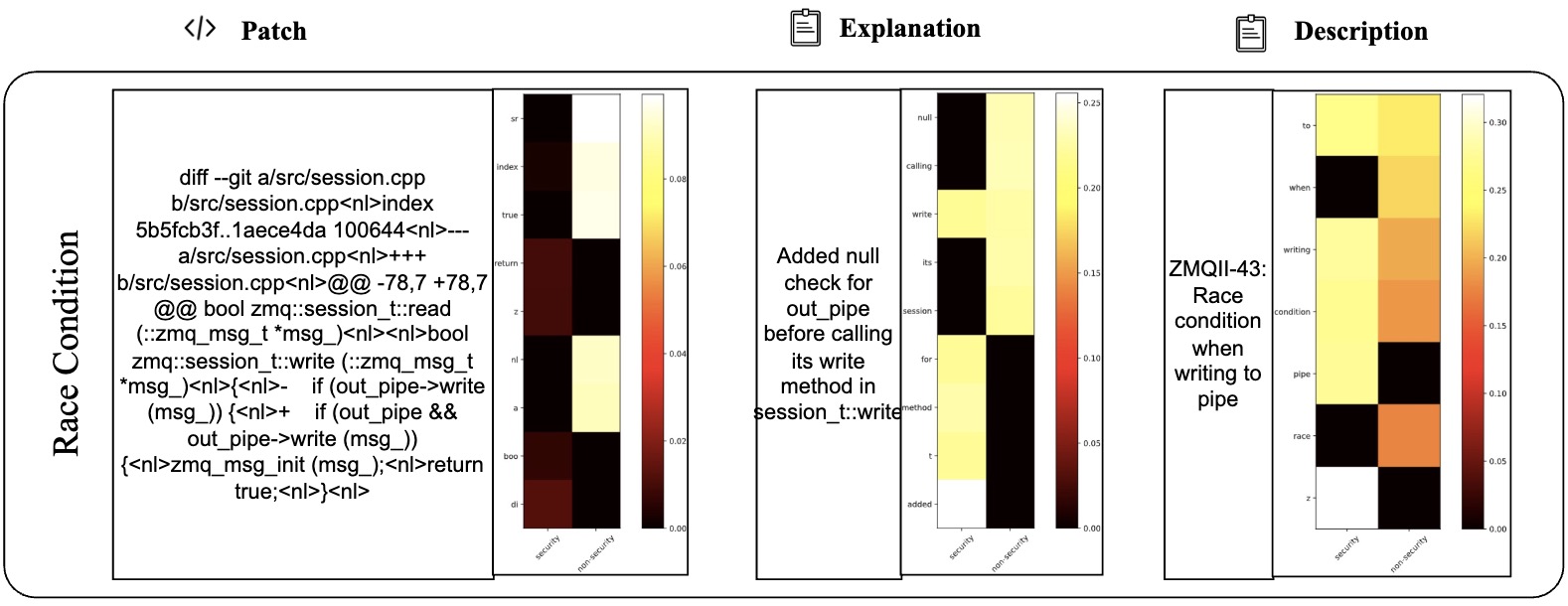
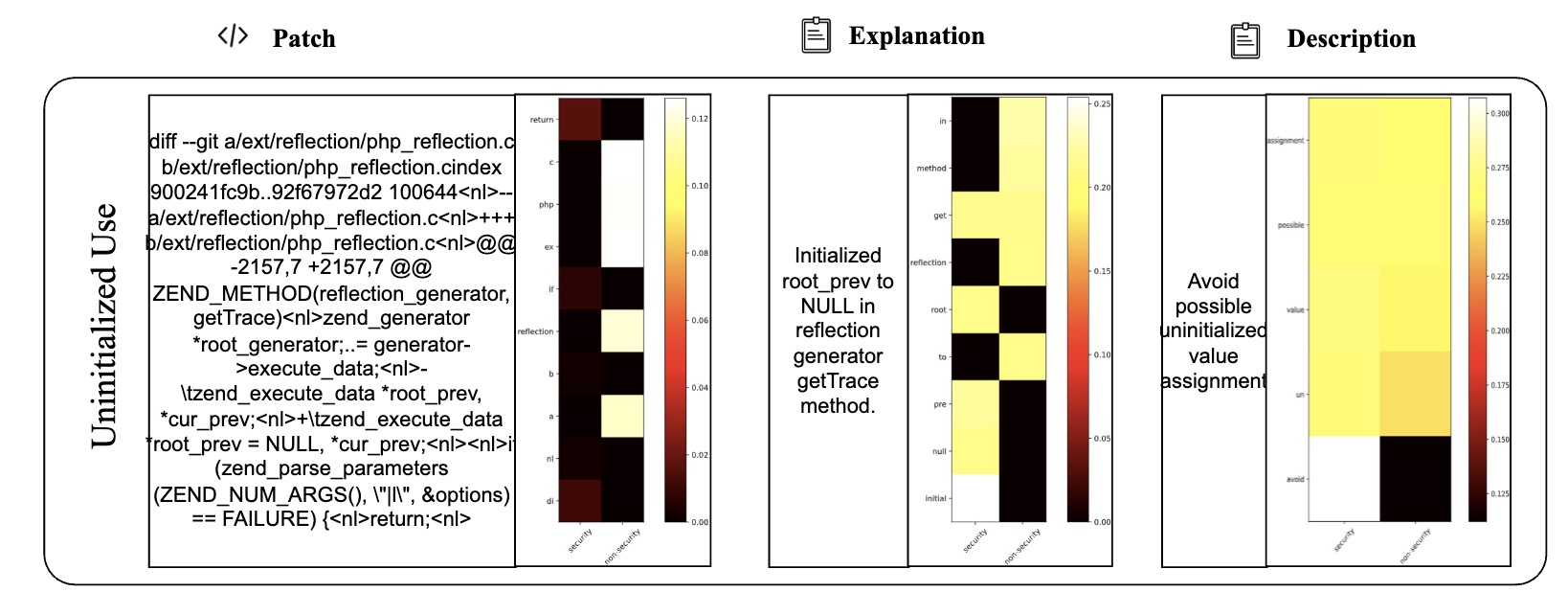
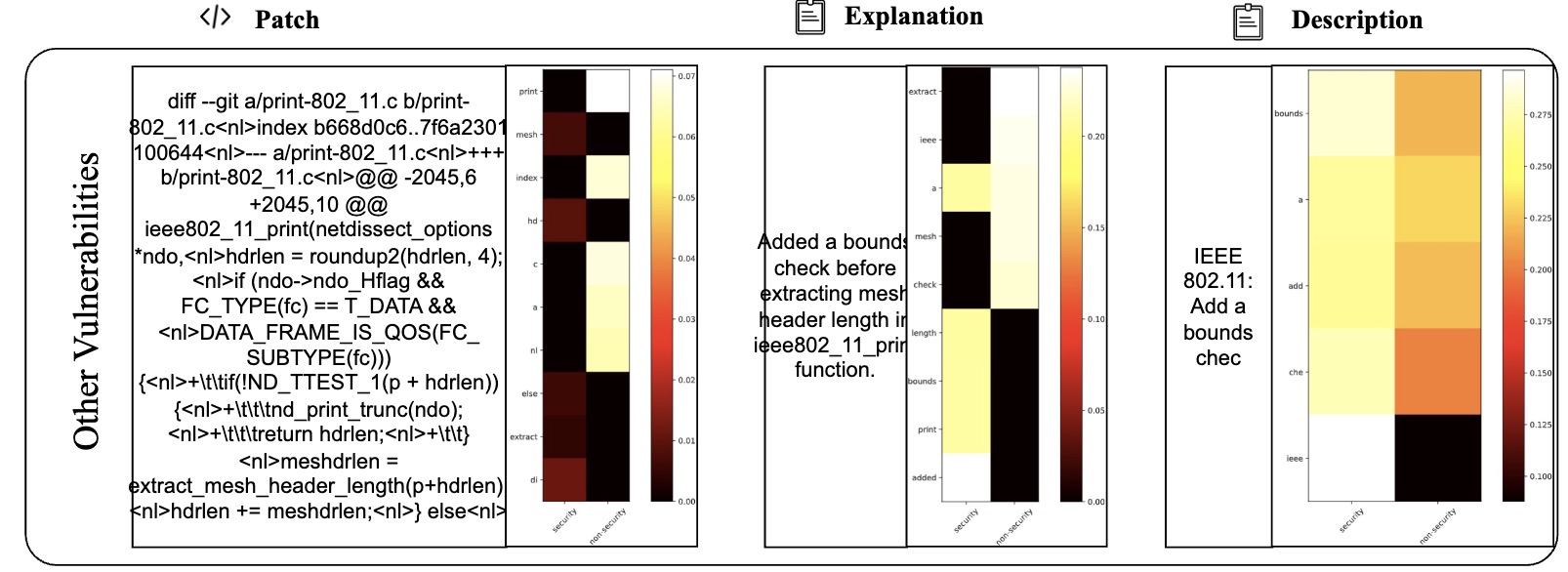
Table VI presents 2 examples to illustrate the difference between LLMDA and GraphSPD in terms of what the representations can capture, and potentially explaining why LLMDA was successful on these cases while GraphSPD was not. For our classification task, we have two labels: security (0) and non-security (1). For LLMDA, we can directly consider the label name in the instruction. Thus we compute the attention map between security and the tokens in the patch, the explanation, and the description. For GraphSPD, however, since there no real label name involved in the training and inference phases, we compute the attention score between the words in the patch and the number “0” or “1”. To simplify the analysis, we only highlight, in Table VI, tokens for which the similarity score is higher than 0.5. As shown in the examples, LLMDA generally assigns high similarity scores to security-related aspects, suggesting a detection capability that nuances between tokens. For example, in the sgminer.c patch, LLMDA gives high scores to realloc and mutex init, indicating a finer sensitivity to potential security implications within these code parts. Similarly, in the krb5/auth context.c patch, the use of memset for initializing authenticator memory is scored high in LLMDA, reflecting its more acute recognition of security practices.
E. Detailed Cases with Attention Map (More lighter mean more matching)